In my previous post on Spark Shuffles, I explored why data movement across the network is the most expensive part of a distributed system. But there is a second, silent performance killer that often sneaks into production pipelines: Redundant Recomputation. To understand why this happens, let’s first take a look at the core of Spark’s execution model: Lazy Evaluation.
Transformation vs. Actions
At a high level, every Spark statement you write can be classified into two types:
- Transformation (Lazy): Statements like .select, .map, .filter or .join don’t actually evaluate the data. They simply help Spark build up its logical plan for how it wants to process the data. These statements can be chained without triggering anything.
- Actions (Eager): Statements like .show, .count, or .write are eager. They force evaluating the data (Spark can’t tell you how many records a dataset has without first computing it).
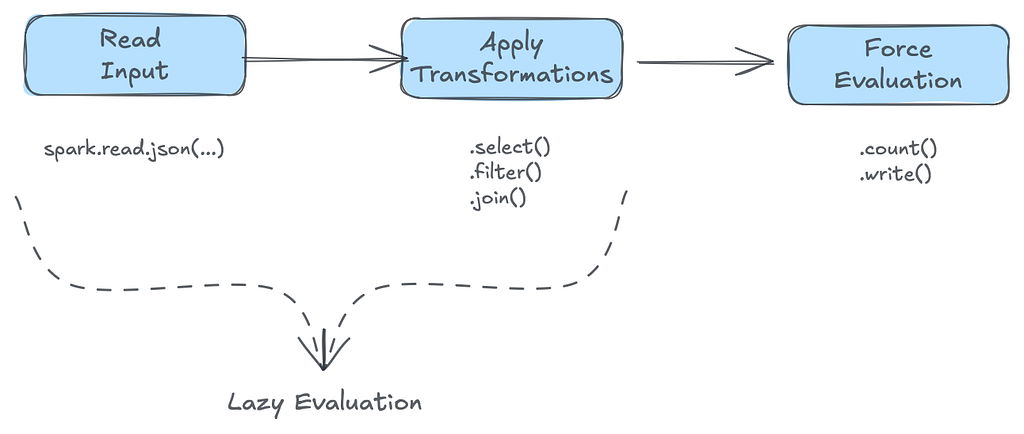
Once an action is finished, Spark discards the materialized results of that computation unless explicitly told to keep them. The logical plan (lineage) still exists — but it will be replayed from the source the next time an action is triggered.
The Branching Problem
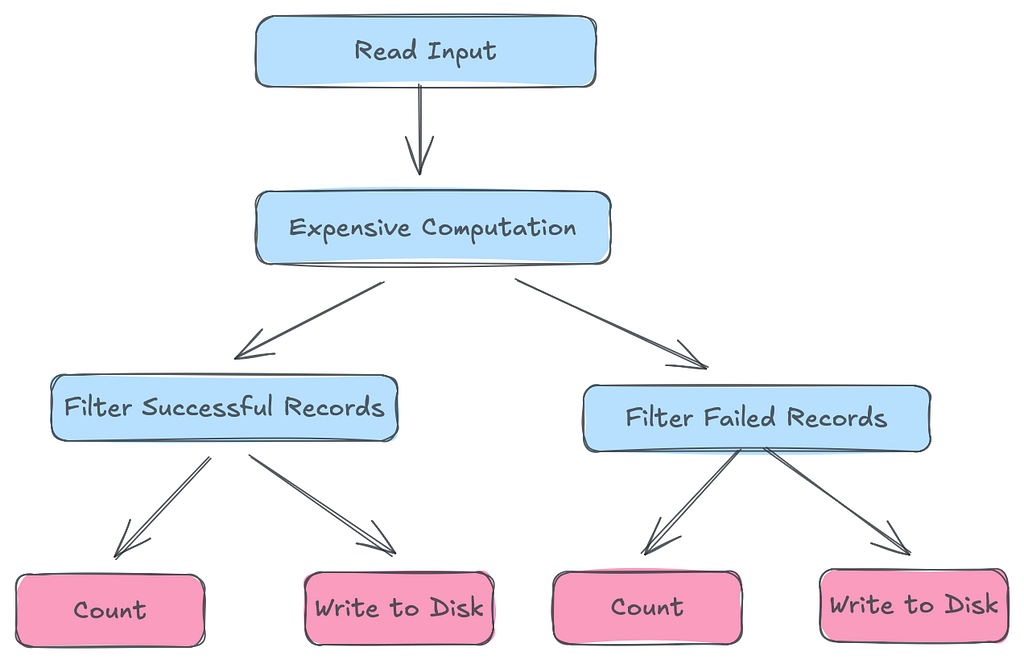
In the real world, processing is rarely linear. A common pattern involves performing an expensive operation — like joining large tables or calling an external API — and then branching that result into “success” and “failed” subsets for different downstream actions.
The Variable Trap: A common misconception is that saving a DataFrame to a variable (e.g., final_df = raw_df.join(..)) physically stores the data. It does not.
In Spark, a variable is simply a pointer to a lineage (DAG), not a container for data. If final_df is used in two different actions, Spark doesn’t “remember” the result from the first time. Because it is lazy, it follows the pointer back to the source and re-executes the entire plan for every single action.
Without caching, every terminal action triggers the DAG from scratch. In the example below, where we load data, apply a heavy join, and split the paths, the DAG is triggered 4 separate times. We pay for that “Expensive Computation” over and over again.
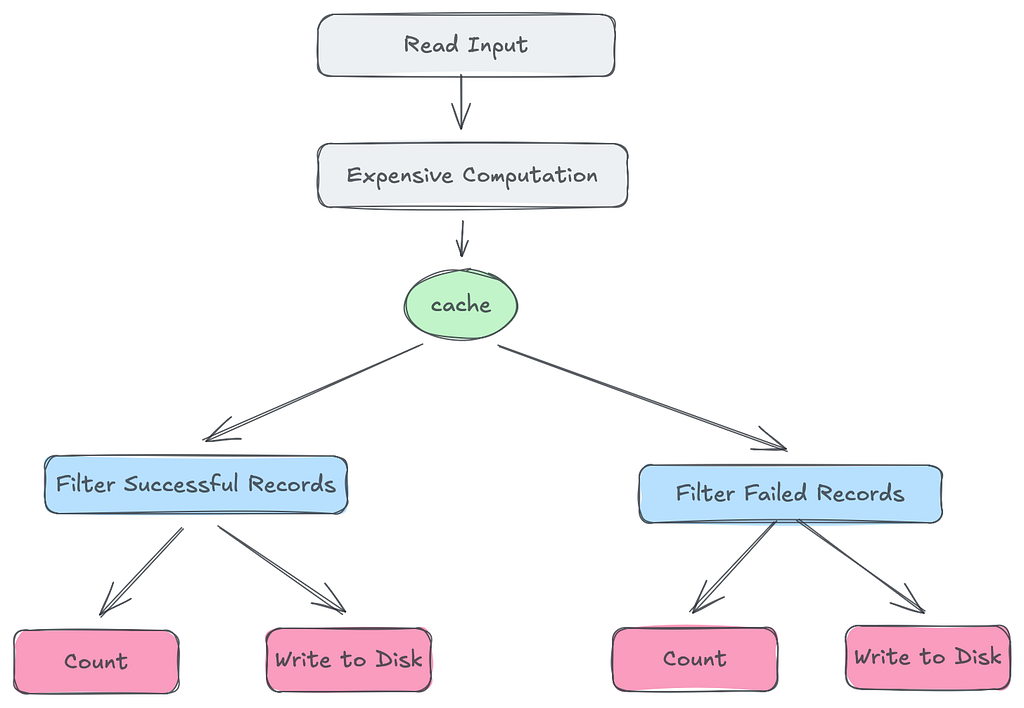
The Solution: Caching Intermediate Datasets
Fortunately, Spark has a simple solution. By calling .cache immediately after an expensive step, you tell Spark to store those intermediate materialized partitions in memory so they can be reused for future actions. The next time an action requests that data, Spark intercepts the request at the cache layer and pulls the results directly from memory, skipping the upstream lineage entirely. It’s important to note that .cache itself is lazy. Spark only materializes the cache the first time an action runs.
The Cost of Caching
- The Memory Tax: By default, datasets are cached in memory. Executor memory is a shared resource split between cached datasets (Storage) and Spark operations (Execution). If the cached datasets become too large, they “squeeze” the space available for shuffles and joins. This forces Spark to either evict the cache or spill operation data to disk, significantly slowing down the job.
- The CPU Cost: By default, Spark data is stored as raw Java objects (unserialized). While there is minimal CPU overhead to read these objects, the memory consumption is huge — often 2–5x the serialized form. If you choose to reduce the memory footprint by serializing the data, you pay back that “saved” memory in CPU overhead.
Choosing the Right Storage Level
Because of these trade-offs, Spark offers granular control over how you choose to cache your datasets using its persist API:
- MEMORY_ONLY: Data is stored in memory only, in an unserialized form. When executor memory is under pressure, the data is evicted from the cache and recomputed when needed.
- MEMORY_ONLY_SER: Data is stored in memory only, but in a serialized form. The memory consumption is significantly lower but requires additional CPU overhead to deserialize the data back when accessed.
- MEMORY_AND_DISK: Data is stored in memory first. If memory is under pressure, the cached data is “spilled” to disk and re-read from disk if needed later.
Caching Strategy
- The Rule of Two: Only cache a dataset if it is going to be used by more than one action or across multiple branches of your DAG.
- Cost to Compute vs. Cost to Read: Don’t cache a dataset if it is massive and recomputing it is faster than reading spilled data.
- Prefer Serialization: If you are operating in a memory-constrained environment, always default to MEMORY_ONLY_SER.
- Clean up Aggressively: Always call .unpersist once downstream actions are complete. Forgotten caches are one of the most common causes of executor OOMs in long-running pipelines.
Final Thoughts
Caching is a powerful construct that can save your job hours in execution time and a ton of hardware cost. But caches are not a silver bullet, and used incorrectly caches are just as likely to bloat your jobs. Mastery of Spark isn’t just about knowing which functions to call; it’s about knowing exactly what those calls cost the cluster under the hood.